Technology
How Much Data is Generated Each Day?
View the full-size version of the infographic

How Much Data is Generated Each Day?
View the full-size version of the infographic by clicking here
You’ve probably heard of kilobytes, megabytes, gigabytes, or even terabytes.
These data units are common everyday amounts that the average person may run into. Units this size may be big enough to quantify the amount of data sent in an email attachment, or the data stored on a hard drive, for example.
In the coming years, however, these common units will begin to seem more quaint – that’s because the entire digital universe is expected to reach 44 zettabytes by 2020.
If this number is correct, it will mean there are 40 times more bytes than there are stars in the observable universe.
A Crash Course in Data
Today’s infographic comes to us from Raconteur, and it gives us a picture of this new data reality.
Before we get to how much data is created each day – both now, and in the future – it’s worth getting acquainted with how data scales in terms of units.
| Abbreviation | Unit | Value | Size (in bytes) |
|---|---|---|---|
| b | bit | 0 or 1 | 1/8 of a byte |
| B | bytes | 8 bits | 1 byte |
| KB | kilobytes | 1,000 bytes | 1,000 bytes |
| MB | megabyte | 1,000² bytes | 1,000,000 bytes |
| GB | gigabyte | 1,000³ bytes | 1,000,000,000 bytes |
| TB | terabyte | 1,000⁴ bytes | 1,000,000,000,000 bytes |
| PB | petabyte | 1,000⁵ bytes | 1,000,000,000,000,000 bytes |
| EB | exabyte | 1,000⁶ bytes | 1,000,000,000,000,000,000 bytes |
| ZB | zettabyte | 1,000⁷ bytes | 1,000,000,000,000,000,000,000 bytes |
| YB | yottabyte | 1,000⁸ bytes | 1,000,000,000,000,000,000,000,000 bytes |
There’s no doubt that data literacy will only become more important in the future, so make sure you know your zettabytes from your yottabytes!
A Day of Data
How much data is generated in a day – and what could this look like as we enter an even more data-driven future?
Here are some key daily statistics highlighted in the infographic:
- 500 million tweets are sent
- 294 billion emails are sent
- 4 petabytes of data are created on Facebook
- 4 terabytes of data are created from each connected car
- 65 billion messages are sent on WhatsApp
- 5 billion searches are made
By 2025, it’s estimated that 463 exabytes of data will be created each day globally – that’s the equivalent of 212,765,957 DVDs per day!
If you think the above information is fascinating, see what happens in an internet minute.



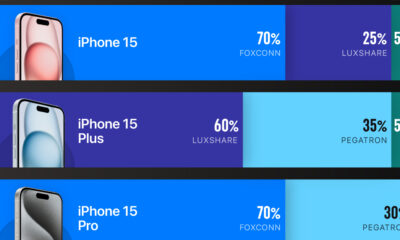
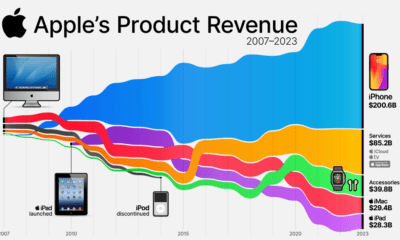



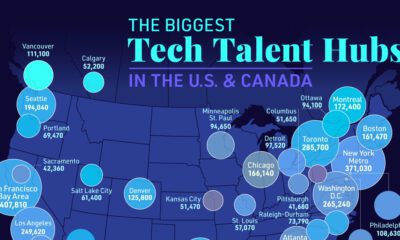


Technology
All of the Grants Given by the U.S. CHIPS Act
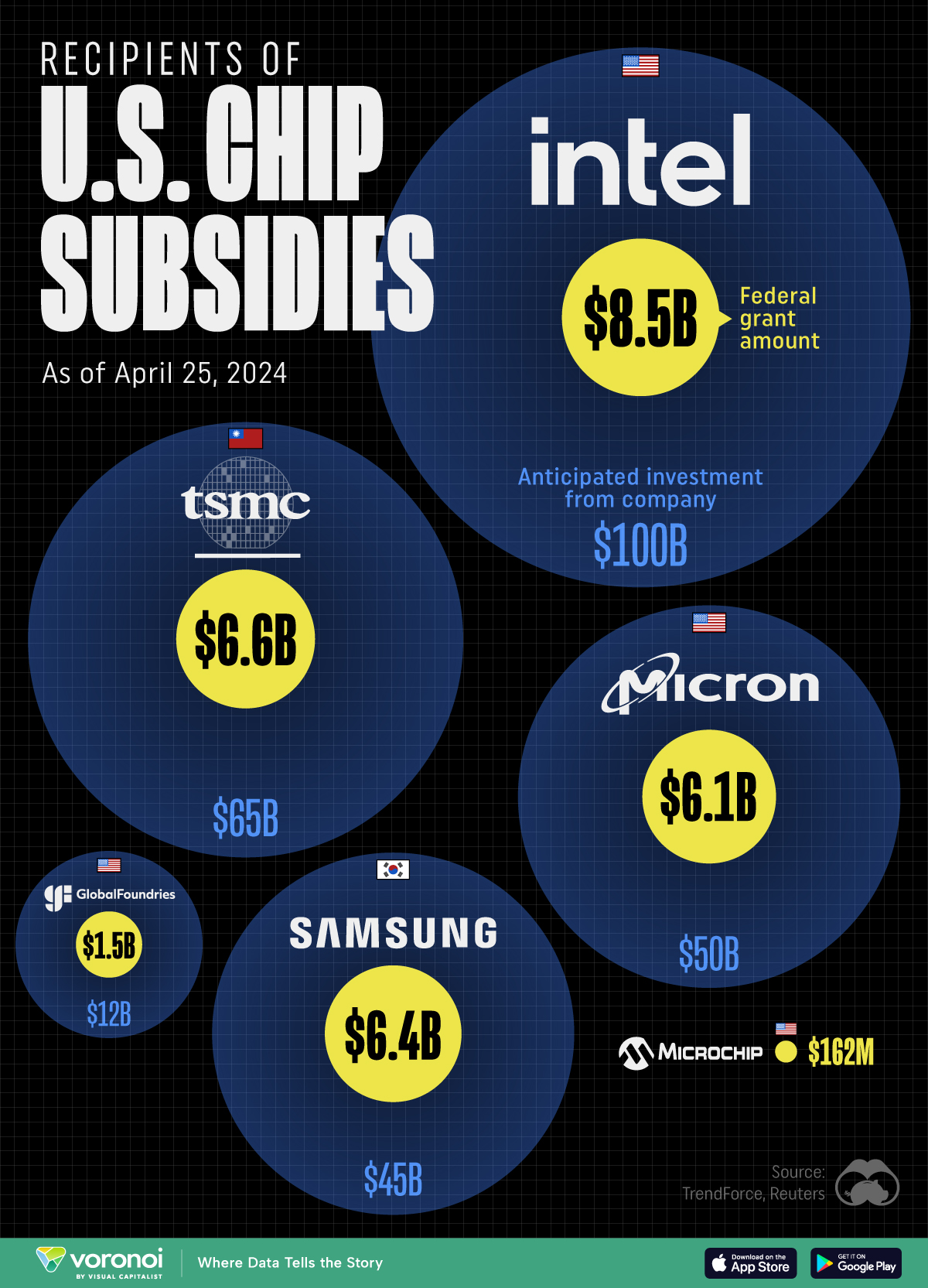
Intel, TSMC, and more have received billions in subsidies from the U.S. CHIPS Act in 2024.

All of the Grants Given by the U.S. CHIPS Act
This was originally posted on our Voronoi app. Download the app for free on iOS or Android and discover incredible data-driven charts from a variety of trusted sources.
This visualization shows which companies are receiving grants from the U.S. CHIPS Act, as of April 25, 2024. The CHIPS Act is a federal statute signed into law by President Joe Biden that authorizes $280 billion in new funding to boost domestic research and manufacturing of semiconductors.
The grant amounts visualized in this graphic are intended to accelerate the production of semiconductor fabrication plants (fabs) across the United States.
Data and Company Highlights
The figures we used to create this graphic were collected from a variety of public news sources. The Semiconductor Industry Association (SIA) also maintains a tracker for CHIPS Act recipients, though at the time of writing it does not have the latest details for Micron.
| Company | Federal Grant Amount | Anticipated Investment From Company |
|---|---|---|
| 🇺🇸 Intel | $8,500,000,000 | $100,000,000,000 |
| 🇹🇼 TSMC | $6,600,000,000 | $65,000,000,000 |
| 🇰🇷 Samsung | $6,400,000,000 | $45,000,000,000 |
| 🇺🇸 Micron | $6,100,000,000 | $50,000,000,000 |
| 🇺🇸 GlobalFoundries | $1,500,000,000 | $12,000,000,000 |
| 🇺🇸 Microchip | $162,000,000 | N/A |
| 🇬🇧 BAE Systems | $35,000,000 | N/A |
BAE Systems was not included in the graphic due to size limitations
Intel’s Massive Plans
Intel is receiving the largest share of the pie, with $8.5 billion in grants (plus an additional $11 billion in government loans). This grant accounts for 22% of the CHIPS Act’s total subsidies for chip production.
From Intel’s side, the company is expected to invest $100 billion to construct new fabs in Arizona and Ohio, while modernizing and/or expanding existing fabs in Oregon and New Mexico. Intel could also claim another $25 billion in credits through the U.S. Treasury Department’s Investment Tax Credit.
TSMC Expands its U.S. Presence
TSMC, the world’s largest semiconductor foundry company, is receiving a hefty $6.6 billion to construct a new chip plant with three fabs in Arizona. The Taiwanese chipmaker is expected to invest $65 billion into the project.
The plant’s first fab will be up and running in the first half of 2025, leveraging 4 nm (nanometer) technology. According to TrendForce, the other fabs will produce chips on more advanced 3 nm and 2 nm processes.
The Latest Grant Goes to Micron
Micron, the only U.S.-based manufacturer of memory chips, is set to receive $6.1 billion in grants to support its plans of investing $50 billion through 2030. This investment will be used to construct new fabs in Idaho and New York.

-

 Education1 week ago
Education1 week agoHow Hard Is It to Get Into an Ivy League School?
-
 Technology2 weeks ago
Technology2 weeks agoRanked: Semiconductor Companies by Industry Revenue Share
-
 Markets2 weeks ago
Markets2 weeks agoRanked: The World’s Top Flight Routes, by Revenue
-

 Demographics2 weeks ago
Demographics2 weeks agoPopulation Projections: The World’s 6 Largest Countries in 2075
-

 Markets2 weeks ago
Markets2 weeks agoThe Top 10 States by Real GDP Growth in 2023
-

 Demographics2 weeks ago
Demographics2 weeks agoThe Smallest Gender Wage Gaps in OECD Countries
-
 Economy2 weeks ago
Economy2 weeks agoWhere U.S. Inflation Hit the Hardest in March 2024
-

 Green2 weeks ago
Green2 weeks agoTop Countries By Forest Growth Since 2001