Technology
How Decentralized Finance Could Make Investing More Accessible
.container {
max-width: 1200px;
}
.button {
display: inline-block;
height: 45px;
color: #ffffff;
text-align: center;
font-family: helvetica;
letter-spacing: .01rem;
text-decoration: none;
white-space: nowrap;
border-radius: 0px;
line-height: 45px;
font-size: em(13);
cursor: pointer;
box-sizing: border-box;
background: #A1E0D7;
transition-duration: 0.4s;
margin-bottom: 1px;
width: 33.33333%;
}
.button-group {
position: left;
width: 100%;
display: inline-block;
list-style: none;
padding: 0;
margin: 0;
/* IE hacks */
zoom: 1;
*display: inline;
}
.button-group li {
float: left;
padding: 0;
margin: 0;
}
.button-group .button {
display: inline-block;
box-sizing: border-box;
color: white;
}
.button-group > .button:not(:first-child):not(:last-child), .button-group li:not(:first-child):not(:last-child) .button {
border-radius: 0;
}
.button-group > .button:first-child, .button-group li:first-child .button {
margin-left: 0;
border-top-right-radius: 0;
border-bottom-right-radius: 0;
}
.button-group > .button:last-child, .button-group li:last-child > .button {
border-top-left-radius: 0;
border-bottom-left-radius: 0;
border-bottom-right-radius: 0;
}
.button:hover {
background-color: #FFC38C;
}
.button.active {
background-color: #FFC38C;
}
.button-group :not(:last-child) {
border-right: 1px solid white;
padding-right: 0px;
}
.button-group {
border-right: none;
margin-right: none;
}
@media (max-width: 600px) {
.button {
font-size: 13px;}
}

Infographic: How Decentralized Finance Could Make Investing More Accessible
Did you know that a majority of the global population doesn’t have access to quality financial assets?
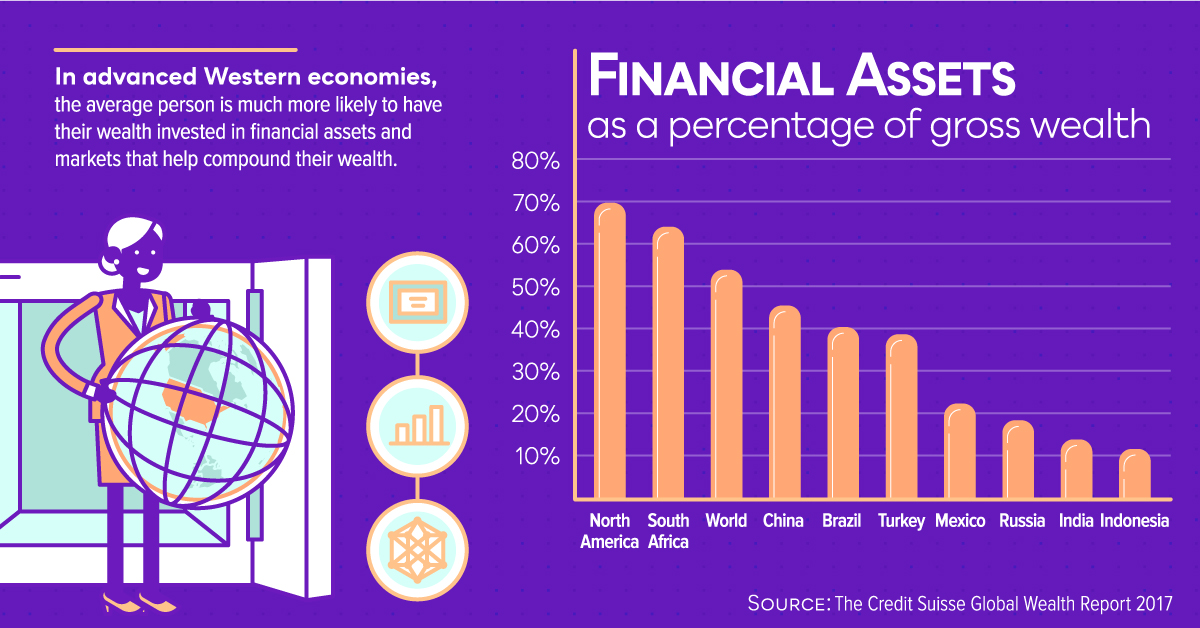
In advanced economies, we are lucky to have simple options to grow and protect our wealth. Banks are all over the place, markets are robust, and we can invest our money into assets like stocks or bonds at the drop of a hat.
In the United States, roughly 52% of people are invested in the stock market – but in a place like India, for example, this portion drops to a paltry 2%. How can we make it possible for people on the “outside” of the financial system to gain access?
Breaking Down Barriers
Today’s infographic comes to us from Abra, and it shows how decentralized finance could make investing a more universal phenomenon, especially for those that don’t have access to the modern financial system.
It lays out four key obstacles that prevent people in developing markets from investing in quality financial assets in the first place:
- The Geographic Lottery
Where you live plays a massive role in determining your ability to build wealth. In advanced Western economies, the average person is much more likely to be invested in financial markets that can help compound wealth. - Financial Literacy and Complexity
Roughly 3.5 billion adults globally lack an understanding of basic financial concepts, which creates an impenetrable barrier to investing. - Local Market Turmoil
Even if a person is mentally prepared to invest, local market turmoil (hyperinflation, political crises, closed borders, etc.) can make it difficult to get access to stable assets. - The Cost of Investing in Foreign Markets
Foreign assets can be pricey. One share of Amazon is $1,800, which is realistically more money than many people around the world can afford.
In other words, there are billions of people globally that can’t take advantage of some of the most effective wealth-building tactics.
This is just one flaw in the current financial system, a paradigm that has created massive amounts of wealth but only for a specific and well-connected group of people.
Enter Decentralized Finance
Could decentralized finance be the alternative to open up access to financial markets?
By combining apps with blockchain technology – specifically through public blockchains such as Bitcoin or Ethereum – decentralized finance makes it possible to get around some of the barriers that are created by more traditional systems.
Here are some of the innovations that are making this possible:
Smart contracts could automate transactions and remove intermediaries, making investing cheaper, faster, and more accessible.
Fractional investing could allow partial or shared ownership of financial assets by using tokenization. This would make expensive stocks like Amazon ($1,800 per share) available to a much wider segment of the population.
Location independent investing is possible through smartphones. This would make it possible for people in remote parts of the developing world to invest, even without access to nearby financial institutions or local markets.
Like the internet with knowledge, decentralized finance could reshape the world by making financial access universal. Who’s ready?






Technology
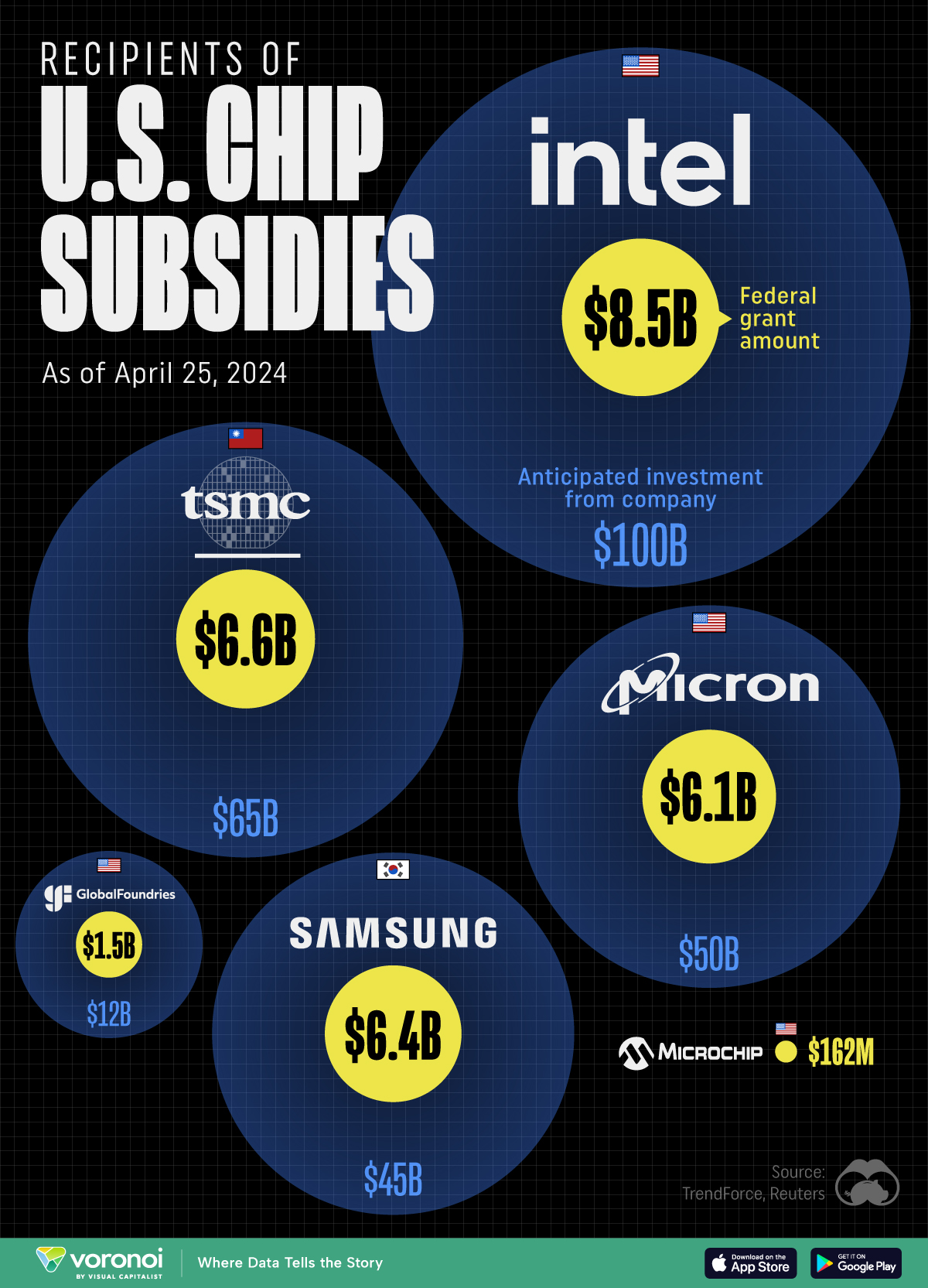
All of the Grants Given by the U.S. CHIPS Act
Intel, TSMC, and more have received billions in subsidies from the U.S. CHIPS Act in 2024.

All of the Grants Given by the U.S. CHIPS Act
This was originally posted on our Voronoi app. Download the app for free on iOS or Android and discover incredible data-driven charts from a variety of trusted sources.
This visualization shows which companies are receiving grants from the U.S. CHIPS Act, as of April 25, 2024. The CHIPS Act is a federal statute signed into law by President Joe Biden that authorizes $280 billion in new funding to boost domestic research and manufacturing of semiconductors.
The grant amounts visualized in this graphic are intended to accelerate the production of semiconductor fabrication plants (fabs) across the United States.
Data and Company Highlights
The figures we used to create this graphic were collected from a variety of public news sources. The Semiconductor Industry Association (SIA) also maintains a tracker for CHIPS Act recipients, though at the time of writing it does not have the latest details for Micron.
| Company | Federal Grant Amount | Anticipated Investment From Company |
|---|---|---|
| 🇺🇸 Intel | $8,500,000,000 | $100,000,000,000 |
| 🇹🇼 TSMC | $6,600,000,000 | $65,000,000,000 |
| 🇰🇷 Samsung | $6,400,000,000 | $45,000,000,000 |
| 🇺🇸 Micron | $6,100,000,000 | $50,000,000,000 |
| 🇺🇸 GlobalFoundries | $1,500,000,000 | $12,000,000,000 |
| 🇺🇸 Microchip | $162,000,000 | N/A |
| 🇬🇧 BAE Systems | $35,000,000 | N/A |
BAE Systems was not included in the graphic due to size limitations
Intel’s Massive Plans
Intel is receiving the largest share of the pie, with $8.5 billion in grants (plus an additional $11 billion in government loans). This grant accounts for 22% of the CHIPS Act’s total subsidies for chip production.
From Intel’s side, the company is expected to invest $100 billion to construct new fabs in Arizona and Ohio, while modernizing and/or expanding existing fabs in Oregon and New Mexico. Intel could also claim another $25 billion in credits through the U.S. Treasury Department’s Investment Tax Credit.
TSMC Expands its U.S. Presence
TSMC, the world’s largest semiconductor foundry company, is receiving a hefty $6.6 billion to construct a new chip plant with three fabs in Arizona. The Taiwanese chipmaker is expected to invest $65 billion into the project.
The plant’s first fab will be up and running in the first half of 2025, leveraging 4 nm (nanometer) technology. According to TrendForce, the other fabs will produce chips on more advanced 3 nm and 2 nm processes.
The Latest Grant Goes to Micron
Micron, the only U.S.-based manufacturer of memory chips, is set to receive $6.1 billion in grants to support its plans of investing $50 billion through 2030. This investment will be used to construct new fabs in Idaho and New York.

-
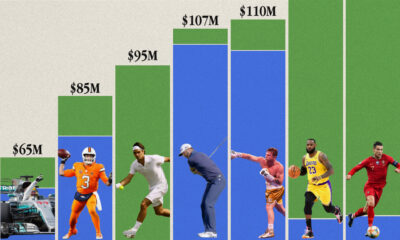
 Sports1 week ago
Sports1 week agoThe Highest Earning Athletes in Seven Professional Sports
-

 Countries2 weeks ago
Countries2 weeks agoPopulation Projections: The World’s 6 Largest Countries in 2075
-

 Markets2 weeks ago
Markets2 weeks agoThe Top 10 States by Real GDP Growth in 2023
-

 Demographics2 weeks ago
Demographics2 weeks agoThe Smallest Gender Wage Gaps in OECD Countries
-
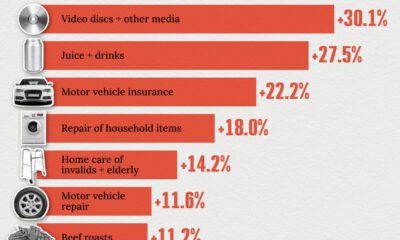
 United States2 weeks ago
United States2 weeks agoWhere U.S. Inflation Hit the Hardest in March 2024
-

 Green2 weeks ago
Green2 weeks agoTop Countries By Forest Growth Since 2001
-
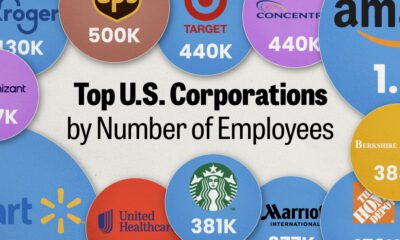
 United States2 weeks ago
United States2 weeks agoRanked: The Largest U.S. Corporations by Number of Employees
-

 Maps2 weeks ago
Maps2 weeks agoThe Largest Earthquakes in the New York Area (1970-2024)