Technology
The Internet of Things and Our Mobile Future

The Internet of Things and Our Mobile Future
By the time you finish reading this infographic, there will be 3,810 new devices connected to the Internet of Things.
That’s because there are 328 million devices being connected to the internet each month. It’s also why researchers estimate that there are going to be 50 billion devices connected by 2020.
In fact, the future looks very different as we adopt to these technological trends. Already, 71% of Americans using wearable technology claim that it has improved their overall health and fitness. Imagine what will happen with more immersive analytics, a preventative mindset, more metrics of useful health functions, and integration into the health system.
The connected lifestyle means that there could be 500 devices in each home connected to the web by 2022. Every lightbulb, lock, thermostat, appliance, and item with an electronic circuit could be networked together, finding synergy. As strange as it may seem, by 2020 researchers even expect 100 million lightbulbs and lamps to be connected to this grid.
Entertainment and convenience are driving the “smart home” concept, which is expected to be worth $56 billion in 2018. However, there is also the benefit of creating a more energy efficient world. It’s already expected that street lamps could save energy costs up to 80%, so why can’t that be the case in the home as well? Self-adjusting thermostats, lights, and appliances will increase the efficiency of homes to make a big impact on net efficiency.
Original graphic by: Mobile Future







Technology
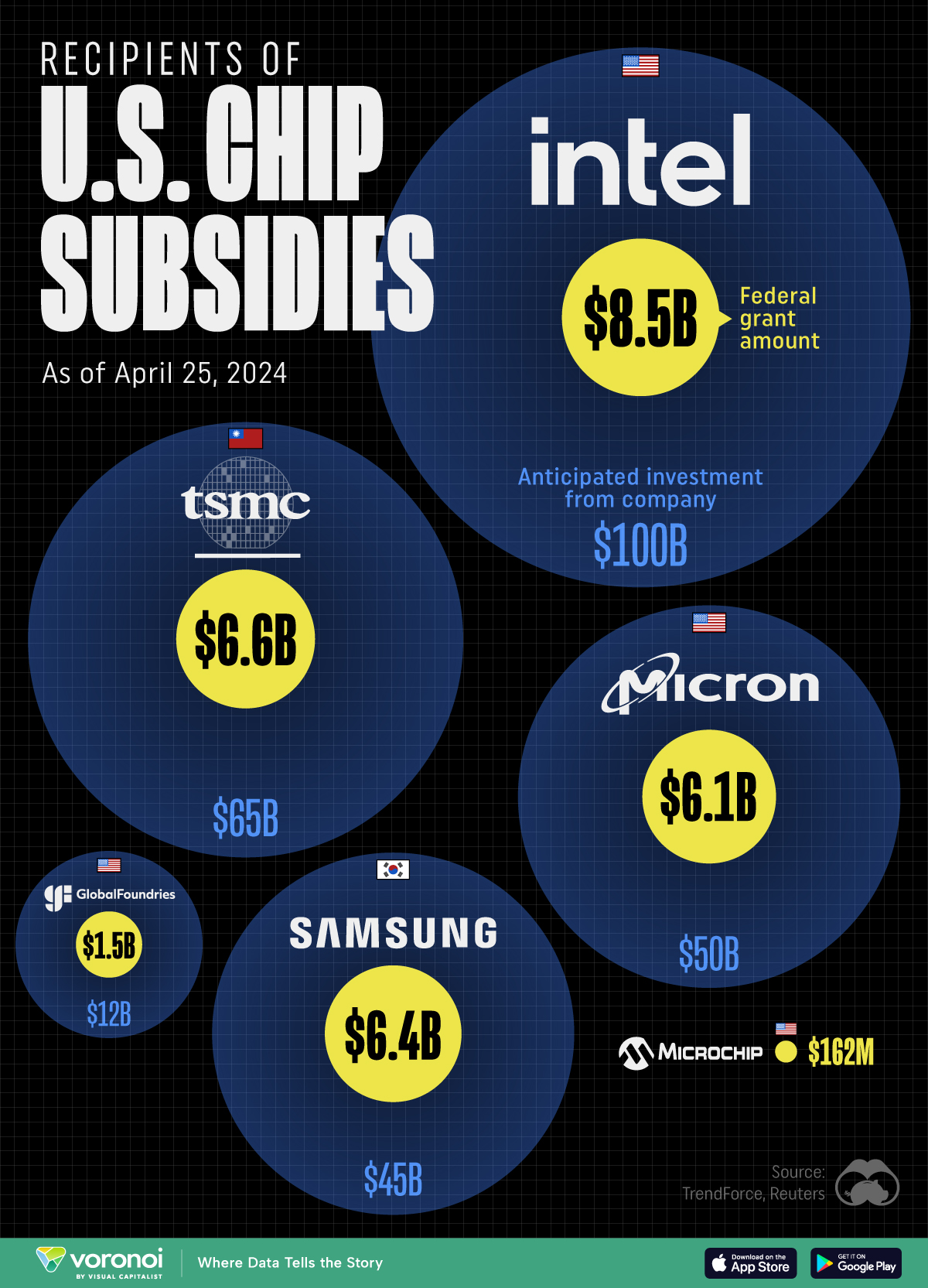
All of the Grants Given by the U.S. CHIPS Act
Intel, TSMC, and more have received billions in subsidies from the U.S. CHIPS Act in 2024.

All of the Grants Given by the U.S. CHIPS Act
This was originally posted on our Voronoi app. Download the app for free on iOS or Android and discover incredible data-driven charts from a variety of trusted sources.
This visualization shows which companies are receiving grants from the U.S. CHIPS Act, as of April 25, 2024. The CHIPS Act is a federal statute signed into law by President Joe Biden that authorizes $280 billion in new funding to boost domestic research and manufacturing of semiconductors.
The grant amounts visualized in this graphic are intended to accelerate the production of semiconductor fabrication plants (fabs) across the United States.
Data and Company Highlights
The figures we used to create this graphic were collected from a variety of public news sources. The Semiconductor Industry Association (SIA) also maintains a tracker for CHIPS Act recipients, though at the time of writing it does not have the latest details for Micron.
| Company | Federal Grant Amount | Anticipated Investment From Company |
|---|---|---|
| 🇺🇸 Intel | $8,500,000,000 | $100,000,000,000 |
| 🇹🇼 TSMC | $6,600,000,000 | $65,000,000,000 |
| 🇰🇷 Samsung | $6,400,000,000 | $45,000,000,000 |
| 🇺🇸 Micron | $6,100,000,000 | $50,000,000,000 |
| 🇺🇸 GlobalFoundries | $1,500,000,000 | $12,000,000,000 |
| 🇺🇸 Microchip | $162,000,000 | N/A |
| 🇬🇧 BAE Systems | $35,000,000 | N/A |
BAE Systems was not included in the graphic due to size limitations
Intel’s Massive Plans
Intel is receiving the largest share of the pie, with $8.5 billion in grants (plus an additional $11 billion in government loans). This grant accounts for 22% of the CHIPS Act’s total subsidies for chip production.
From Intel’s side, the company is expected to invest $100 billion to construct new fabs in Arizona and Ohio, while modernizing and/or expanding existing fabs in Oregon and New Mexico. Intel could also claim another $25 billion in credits through the U.S. Treasury Department’s Investment Tax Credit.
TSMC Expands its U.S. Presence
TSMC, the world’s largest semiconductor foundry company, is receiving a hefty $6.6 billion to construct a new chip plant with three fabs in Arizona. The Taiwanese chipmaker is expected to invest $65 billion into the project.
The plant’s first fab will be up and running in the first half of 2025, leveraging 4 nm (nanometer) technology. According to TrendForce, the other fabs will produce chips on more advanced 3 nm and 2 nm processes.
The Latest Grant Goes to Micron
Micron, the only U.S.-based manufacturer of memory chips, is set to receive $6.1 billion in grants to support its plans of investing $50 billion through 2030. This investment will be used to construct new fabs in Idaho and New York.

-

 Debt1 week ago
Debt1 week agoHow Debt-to-GDP Ratios Have Changed Since 2000
-
 Markets2 weeks ago
Markets2 weeks agoRanked: The World’s Top Flight Routes, by Revenue
-

 Countries2 weeks ago
Countries2 weeks agoPopulation Projections: The World’s 6 Largest Countries in 2075
-

 Markets2 weeks ago
Markets2 weeks agoThe Top 10 States by Real GDP Growth in 2023
-

 Demographics2 weeks ago
Demographics2 weeks agoThe Smallest Gender Wage Gaps in OECD Countries
-
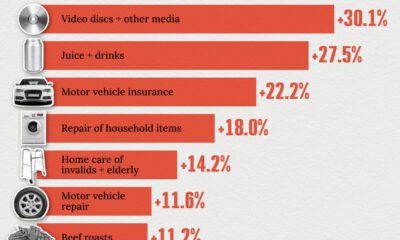
 United States2 weeks ago
United States2 weeks agoWhere U.S. Inflation Hit the Hardest in March 2024
-

 Green2 weeks ago
Green2 weeks agoTop Countries By Forest Growth Since 2001
-
 United States2 weeks ago
United States2 weeks agoRanked: The Largest U.S. Corporations by Number of Employees