Technology
Visualizing the Power of the World’s Supercomputers




Visualizing the Power of the World’s Supercomputers
A supercomputer is a machine that is built to handle billions, if not trillions of calculations at once. Each supercomputer is actually made up of many individual computers (known as nodes) that work together in parallel.
A common metric for measuring the performance of these machines is flops, or floating point operations per second.
In this visualization, we’ve used November 2021 data from TOP500 to visualize the computing power of the world’s top five supercomputers. For added context, a number of modern consumer devices were included in the comparison.
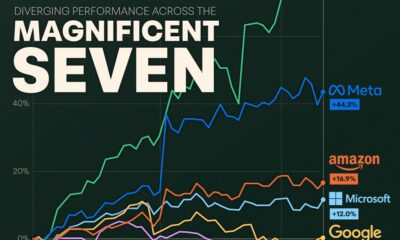
Ranking by Teraflops
Because supercomputers can achieve over one quadrillion flops, and consumer devices are much less powerful, we’ve used teraflops as our comparison metric.
1 teraflop = 1,000,000,000,000 (1 trillion) flops.
| Rank | Name | Type | Teraflops |
|---|---|---|---|
| #1 | 🇯🇵 Supercomputer Fugaku | Supercomputer | 537,212 |
| #2 | 🇺🇸 Summit | Supercomputer | 200,795 |
| #3 | 🇺🇸 Sierra | Supercomputer | 125,712 |
| #4 | 🇨🇳 Sunway Taihulight | Supercomputer | 125,436 |
| #5 | 🇺🇸 Perlmutter | Supercomputer | 93,750 |
| n/a | Nvidia Titan RTX | Consumer device | 130 |
| n/a | Nvidia GeForce RTX 3090 | Consumer device | 36 |
| n/a | Xbox Series X | Consumer device | 12 |
| n/a | Tesla Model S (2021) | Consumer device | 10 |
Supercomputer Fugaku was completed in March 2021, and is officially the world’s most powerful supercomputer. It’s used for various applications, including weather simulations and innovative drug discovery.
Sunway Taihulight is officially China’s top supercomputer and fourth most powerful in the world. That said, some experts believe that the country is already operating two much more powerful systems, based on data from anonymous sources.
As you can see, the most advanced consumer devices do not come close to supercomputing power. For example, it would take the combined power of 4,000 Nvidia Titan RTX graphics cards (the most powerful consumer card available) to measure up to the Fugaku.
Upcoming Supercomputers
One of China’s unrevealed supercomputers is supposedly named Oceanlite, and is a successor to Sunway Taihulight. It’s believed to have reached 1.3 exaflops, or 1.3 quintillion flops. The following table makes it easier to follow all of these big numbers.
| Name | Notation | Exponent | Prefix |
|---|---|---|---|
| Quintillion | 1,000,000,000,000,000,000 | 10^18 | Exa |
| Quadrillion | 1,000,000,000,000,000 | 10^15 | Peta |
| Trillion | 1,000,000,000,000 | 10^12 | Tera |
| Billion | 1,000,000,000 | 10^9 | Giga |
| Million | 1,000,000 | 10^6 | Mega |
In the U.S., rival chipmakers AMD and Intel have both won contracts from the U.S. Department of Energy to build exascale supercomputers. On the AMD side, there’s Frontier and El Capitan, while on the Intel side, there’s Aurora.
Also involved in the EL Capitan project is Hewlett Packard Enterprise (HPE), which claims the supercomputer will be able to reach 2 exaflops upon its completion in 2023. All of this power will be used to support several exciting endeavors:
- Enable advanced simulation and modeling to support the U.S. nuclear stockpile and ensure its reliability and security.
- Accelerate cancer drug discovery from six years to one year through a partnership with pharmaceutical company, GlaxoSmithKline
- Understand the dynamic and mutations of RAS proteins that are linked to 30% of human cancers
Altogether, exascale computing represents the ability to conduct complex analysis in a matter of seconds, rather than hours. This could unlock an even faster pace of innovation.





Technology
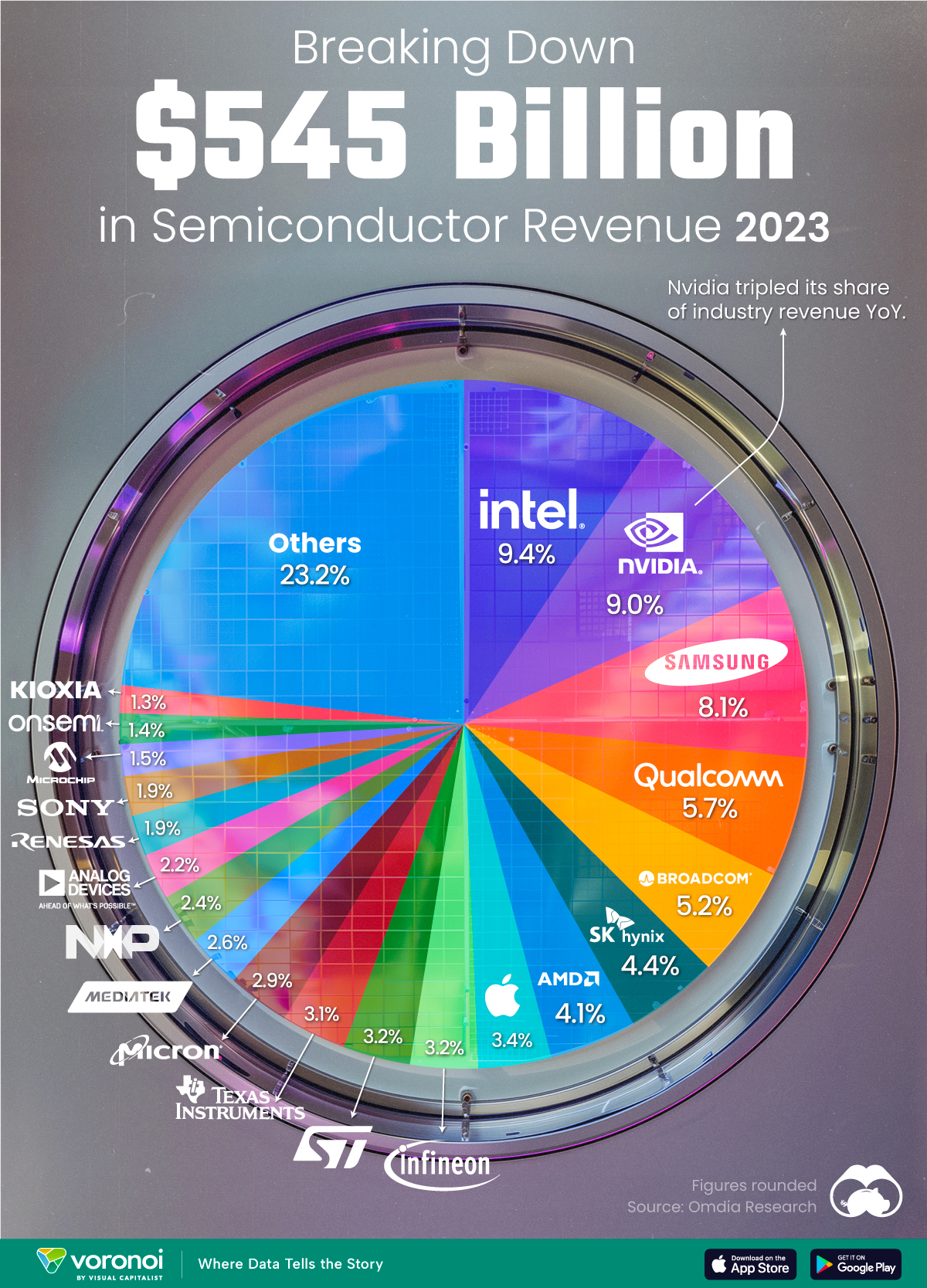
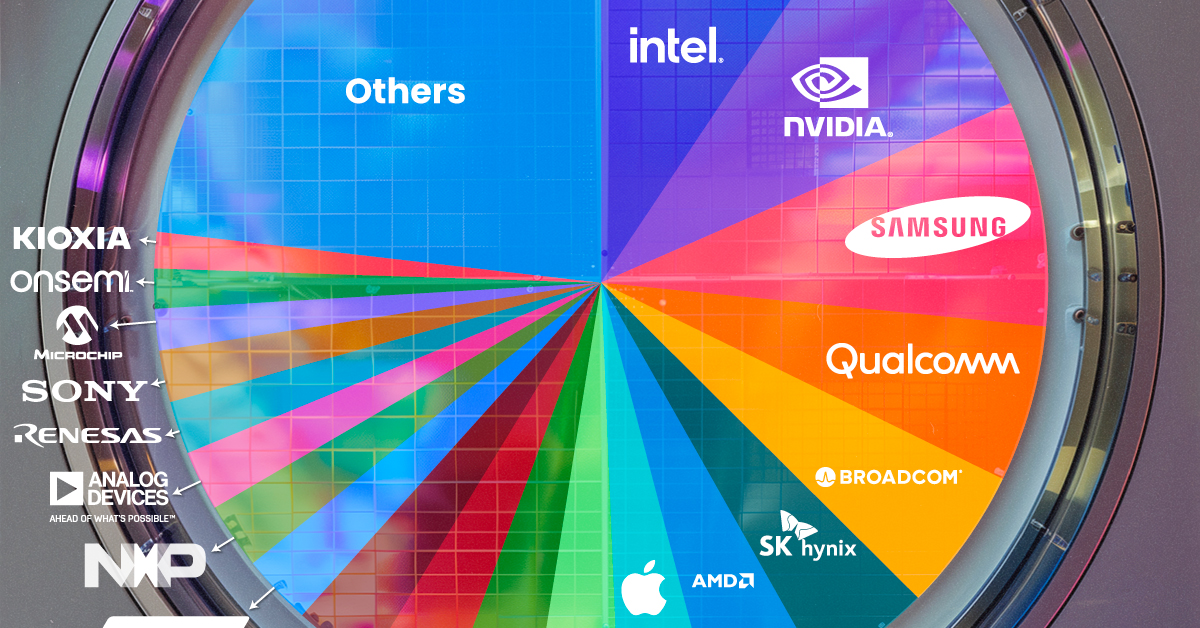
Ranked: Semiconductor Companies by Industry Revenue Share
Nvidia is coming for Intel’s crown. Samsung is losing ground. AI is transforming the space. We break down revenue for semiconductor companies.
Semiconductor Companies by Industry Revenue Share
This was originally posted on our Voronoi app. Download the app for free on Apple or Android and discover incredible data-driven charts from a variety of trusted sources.
Did you know that some computer chips are now retailing for the price of a new BMW?
As computers invade nearly every sphere of life, so too have the chips that power them, raising the revenues of the businesses dedicated to designing them.
But how did various chipmakers measure against each other last year?
We rank the biggest semiconductor companies by their percentage share of the industry’s revenues in 2023, using data from Omdia research.
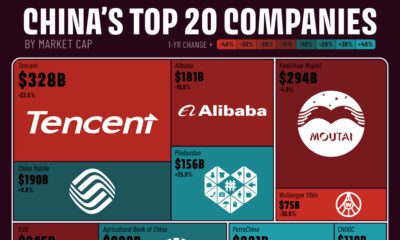
Which Chip Company Made the Most Money in 2023?
Market leader and industry-defining veteran Intel still holds the crown for the most revenue in the sector, crossing $50 billion in 2023, or 10% of the broader industry’s topline.
All is not well at Intel, however, with the company’s stock price down over 20% year-to-date after it revealed billion-dollar losses in its foundry business.
| Rank | Company | 2023 Revenue | % of Industry Revenue |
|---|---|---|---|
| 1 | Intel | $51B | 9.4% |
| 2 | NVIDIA | $49B | 9.0% |
| 3 | Samsung Electronics | $44B | 8.1% |
| 4 | Qualcomm | $31B | 5.7% |
| 5 | Broadcom | $28B | 5.2% |
| 6 | SK Hynix | $24B | 4.4% |
| 7 | AMD | $22B | 4.1% |
| 8 | Apple | $19B | 3.4% |
| 9 | Infineon Tech | $17B | 3.2% |
| 10 | STMicroelectronics | $17B | 3.2% |
| 11 | Texas Instruments | $17B | 3.1% |
| 12 | Micron Technology | $16B | 2.9% |
| 13 | MediaTek | $14B | 2.6% |
| 14 | NXP | $13B | 2.4% |
| 15 | Analog Devices | $12B | 2.2% |
| 16 | Renesas Electronics Corporation | $11B | 1.9% |
| 17 | Sony Semiconductor Solutions Corporation | $10B | 1.9% |
| 18 | Microchip Technology | $8B | 1.5% |
| 19 | Onsemi | $8B | 1.4% |
| 20 | KIOXIA Corporation | $7B | 1.3% |
| N/A | Others | $126B | 23.2% |
| N/A | Total | $545B | 100% |
Note: Figures are rounded. Totals and percentages may not sum to 100.
Meanwhile, Nvidia is very close to overtaking Intel, after declaring $49 billion of topline revenue for 2023. This is more than double its 2022 revenue ($21 billion), increasing its share of industry revenues to 9%.
Nvidia’s meteoric rise has gotten a huge thumbs-up from investors. It became a trillion dollar stock last year, and broke the single-day gain record for market capitalization this year.
Other chipmakers haven’t been as successful. Out of the top 20 semiconductor companies by revenue, 12 did not match their 2022 revenues, including big names like Intel, Samsung, and AMD.
The Many Different Types of Chipmakers
All of these companies may belong to the same industry, but they don’t focus on the same niche.
According to Investopedia, there are four major types of chips, depending on their functionality: microprocessors, memory chips, standard chips, and complex systems on a chip.
Nvidia’s core business was once GPUs for computers (graphics processing units), but in recent years this has drastically shifted towards microprocessors for analytics and AI.
These specialized chips seem to be where the majority of growth is occurring within the sector. For example, companies that are largely in the memory segment—Samsung, SK Hynix, and Micron Technology—saw peak revenues in the mid-2010s.

-

 Mining2 weeks ago
Mining2 weeks agoCharted: The Value Gap Between the Gold Price and Gold Miners
-

 Real Estate1 week ago
Real Estate1 week agoRanked: The Most Valuable Housing Markets in America
-

 Business1 week ago
Business1 week agoCharted: Big Four Market Share by S&P 500 Audits
-
 AI1 week ago
AI1 week agoThe Stock Performance of U.S. Chipmakers So Far in 2024
-
 Misc1 week ago
Misc1 week agoAlmost Every EV Stock is Down After Q1 2024
-

 Money2 weeks ago
Money2 weeks agoWhere Does One U.S. Tax Dollar Go?
-

 Green2 weeks ago
Green2 weeks agoRanked: Top Countries by Total Forest Loss Since 2001
-
 Real Estate2 weeks ago
Real Estate2 weeks agoVisualizing America’s Shortage of Affordable Homes